




Badanie populacji
Badanie to było częścią szwedzkiego interdyscyplinarnego projektu panelowego (SIP), obejmującego bazę danych na poziomie indywidualnym, zarządzaną w Centrum Demografii Ekonomicznej na Uniwersytecie w Lund. Dzięki unikalnemu szwedzkiemu numerowi identyfikacyjnemu nadawanemu przy urodzeniu lub imigracji tworzonych jest kilka krajowych rejestrów, takich jak Szwedzki Medyczny Rejestr Urodzeń (MBR), Szwedzki Krajowy Rejestr Pacjentów (NPR), Rejestr Populacji Ogółem (TPR) i Edukacja Rejestr Partycypacji (TPR) Łączy UREG z rejestrem wielopokoleniowym, umożliwiając unikalny szczegółowy i przekrojowy opis charakterystyki zdrowotnej i społeczno-ekonomicznej populacji. Wyodrębniliśmy kohortę populacyjną składającą się ze wszystkich kobiet urodzonych w latach 1962–1980 (N = 1 352 019), łącząc je z rodzicami i biologicznym rodzeństwem.
Wykluczono porody mnogie i kobiety z brakującym ogniwem któregokolwiek z rodziców biologicznych (N=330, 378). Wykluczyliśmy także osoby, które zmarły lub wyemigrowały przed 17. rokiem życia lub przed rozpoczęciem okresu obserwacji (N = 45 467), którzy nie byli objęci okresem obserwacji (1997-2011)(N = 50 396). Po wykluczeniu tych, którym brakowało informacji o zmiennych objaśniających oraz tych, które nie miały co najmniej jednej pełnej biologicznej siostry, utworzono dwie podpróby. Jedna składała się z kobiet, które miały co najmniej jedną pełną siostrę (próba sióstr: N = 333 999) i druga z dodatkowymi ograniczeniami dotyczącymi kobiet, zawierająca informacje o cechach mierzonych przy urodzeniu, pobrana z MBR, co oznacza, że uwzględnione są tylko kobiety urodzone w Szwecji i urodzone w latach 1973-1980 (próba MBR Sister: N = 77 034). Schemat blokowy na rysunku 1 pokazuje, w jaki sposób generowane są próbki analityczne.
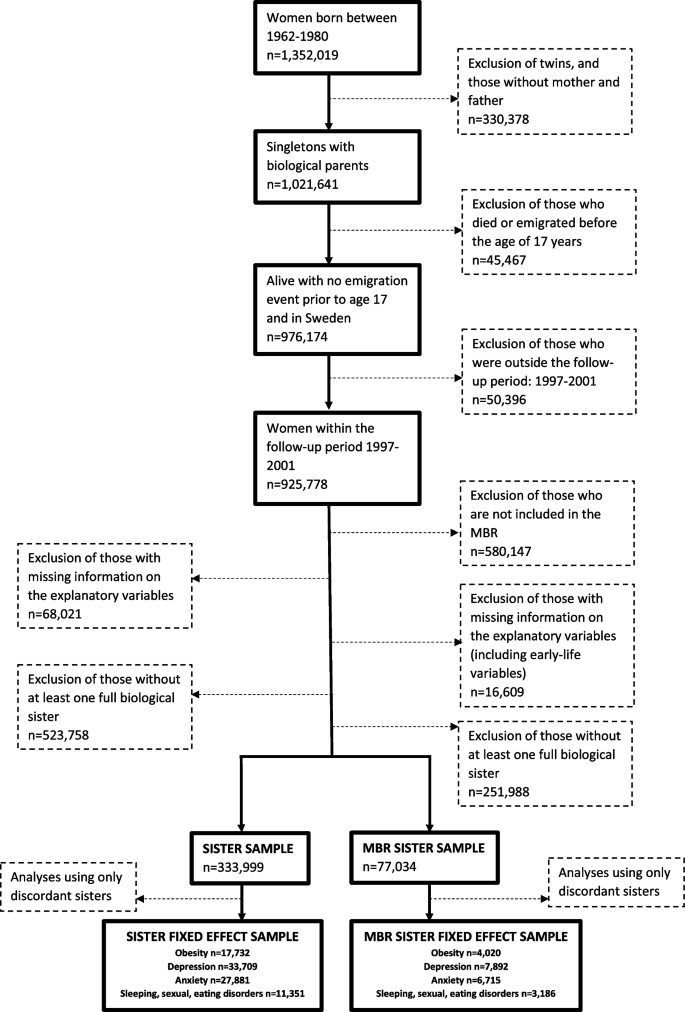
Schemat blokowy tworzenia próbki badawczej
Okres obserwacji rozpoczął się 1 stycznia 1997 r., kiedy w tym samym roku w Szwecji wprowadzono do użytku 10 kodów Międzynarodowej Klasyfikacji Chorób (ICD), przy czym próba była ograniczona do kobiet w wieku 17–45 lat. Badaną populację obserwowano w sposób ciągły aż do tego, co nastąpi wcześniej: wiek 45 lat, śmierć, emigracja lub koniec okresu obserwacji 31 grudnia 2011 r. Rycina 2 przedstawia próbki użyte w różnych częściach analizy, a także pokazuje odpowiednie okresy dostępności danych w szwedzkich rejestrach administracyjnych.
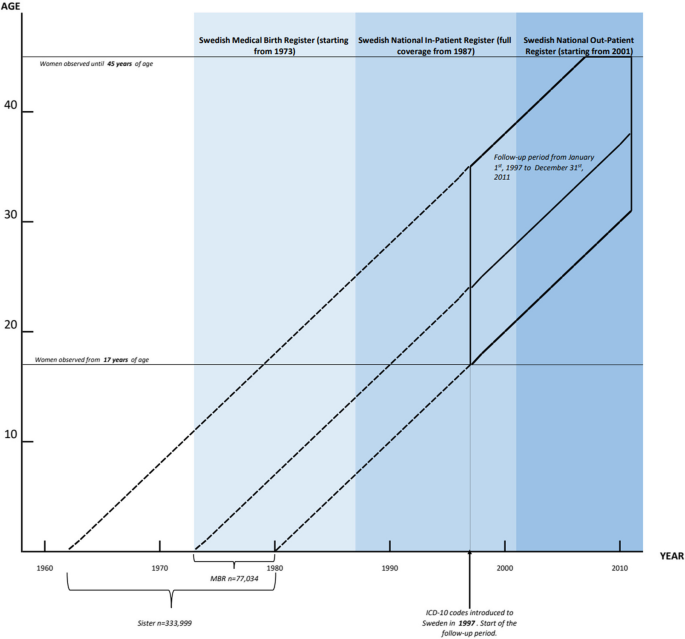
Dostępność danych ze szwedzkich rejestrów krajowych i okien pobierania próbek
Wynik: Zmienne dotyczące chorób współistniejących
Za pomocą NPR zidentyfikowaliśmy następujące potencjalne choroby współistniejące, posługując się kodami diagnostycznymi ICD-10: otyłość (E66), depresja (F32 – epizod depresyjny, F33 – zaburzenie depresyjne nawracające), stany lękowe (F41 – inne zaburzenia lękowe) oraz zaburzenia SSE ( F51 – zaburzenie depresyjne.Sen nieorganiczny, F52 – impotencja niespowodowana dysfunkcją lub chorobą organiczną, F50 – zaburzenia odżywiania). Każdy przypadek zdefiniowano jako zmienną binarną, wskazującą, czy u danej osoby zdiagnozowano kiedykolwiek w okresie obserwacji, a niekoniecznie po rozpoznaniu PCOS.
Narażenie: Zespół policystycznych jajników i kryteria wykluczenia
PCOS zidentyfikowano za pomocą NPR [36] W dowolnym momencie obserwacji jako ekspozycja binarna, w tym diagnozy szpitalne i ambulatoryjne (E28), przy czym zdecydowana większość diagnoz pochodzi z danych pacjentów ambulatoryjnych (99,7%). Zastosowano łączony kod ICD-10 E28 ze względu na ograniczony dostęp do bardziej szczegółowego kodu diagnostycznego PCOS (ICD-10: E28.2). Kobiety, u których zdiagnozowano stany, które mogą powodować objawy podobne do zespołu policystycznych jajników, w tym zespół Turnera (Q96), złośliwy nowotwór jajnika (C56), guz nadnerczy (C74), zespół nadnerczowo-płciowy (E25) i choroba Cushinga (E24) oraz nadmierne wydzielanie przysadka mózgowa (E22). , zostały wyłączone, aby zapewnić prywatność, podobnie jak w poprzedniej literaturze [37]. Uwzględniono zarówno diagnozy główne, jak i dodatkowe. Do naszej głównej analizy włączyliśmy jedynie kobiety, u których nie zdiagnozowano żadnego z kryteriów wykluczenia, niezależnie od tego, czy schorzenia te wystąpiły przed rozpoznaniem PCOS, czy po nim.
Współzmienne
Charakterystyka rodziny
Najwyższy poziom wykształcenia matki i ojca uzyskano z UREG i sklasyfikowano go jako wykształcenie podstawowe, średnie lub wyższe i wykorzystano go jako wskaźnik statusu społeczno-ekonomicznego ich córek w dzieciństwie. Kraj urodzenia matki, ojca i potomstwa uzyskano z TPR i zagregowano jako zmienną trójstopniową dla Szwecji; Europa, Ameryka Północna i Oceania; Afryce, Azji i Ameryce Południowej. Kolejność urodzeń została utworzona na podstawie żywych narodzin matki i pogrupowana jako pierworodne, drugie i trzecie lub starsze. Wiek matki w chwili urodzenia podzielono na ≥18 lat, 19–35 lat i ≥36 lat.
Charakterystyka dorosłych
Najwyższy poziom wykształcenia, jaki uzyskała jednostka, pobierany był z UREG i zaliczany do podstawowego/średniego lub wyższego. Stan cywilny został zaczerpnięty z TPR i zastosowany do rozróżnienia pomiędzy osobą pozostającą w związku małżeńskim/w zarejestrowanym związku partnerskim lub osobą samotną/niebędącą w związku małżeńskim w zarejestrowanym związku partnerskim, stosując stan cywilny dla najwyższego obserwowanego wieku od 17 do 45 lat. Ponadto ostateczne modele skorygowano o wskaźnik zamieszkania kobiet w momencie obserwacji, podczas której łączono status pobytu w obecnych 21 okręgach.
Czynniki wczesnego życia
Z MBR wyodrębniono masę urodzeniową, 1-minutową punktację w skali Apgar i wiek ciążowy. Masę urodzeniową podzielono na grupy o masie ciała 500 g (≥2499 g, 2500–2999 g, 3000–3499 g, 3500–3999 g, 4000–4499 g i ≥4500 g). Wiek ciążowy mierzono w pełnych tygodniach ciąży i podzielono na skrajnie przedwczesny (<28 tygodni), skrajnie przedwczesny (28–32 tygodni), umiarkowany lub późny przedwczesny (33–36 tygodni) i całkowity wcześniak (37–41 tygodni). i wcześniaków (37-41 tygodni). Poród poporodowy (≥42 tygodnie). Wiek ciążowy ustala się na podstawie samodzielnie zgłaszanych pierwszych dat ostatniej miesiączki lub wyników badań USG. 1-minutową punktację w skali Apgar sklasyfikowano jako 10, 9, 8 i mniejszą lub równą 7, jako standaryzowaną ocenę markerów stanu zdrowia noworodków bezpośrednio po urodzeniu. [38].
Analiza statystyczna
Analizy statystyczne przeprowadzono przy użyciu programu STATA/MP 17.0 (StataCorp). Główne analizy ograniczono do osób, którym nie brakowało informacji na temat wszystkich współzmiennych uwzględnionych w modelach.
Aby osiągnąć pierwszy cel badania, potraktowaliśmy siostry jako osoby niespokrewnione i dlatego zastosowaliśmy bezwarunkową regresję logistyczną w celu zbadania związku między PCOS a każdą chorobą współistniejącą w próbie rodzeństwa, kontrolując wcześniej określone współzmienne. Do zestawu modeli dodano współzmienne, począwszy od kontroli roku urodzenia, po pochodzenie rodzinne i cechy osoby dorosłej. Ponadto te same modele przetestowano na próbie, która nie ograniczała się do pełnych sióstr.
Aby osiągnąć drugi cel, czyli porównać powiązania między PCOS a chorobami współistniejącymi badanymi u pełnego rodzeństwa, zastosowano regresję logistyczną FE (znaną również jako warunkowa regresja logistyczna). Odpowiada to za niezaobserwowane, niezmienne w czasie czynniki, które pochodzą ze wspólnych rodzinnych czynników środowiskowych, społecznych lub genetycznych, które mogą wpływać zarówno na PCOS, jak i wybraną chorobę współistniejącą.
Potencjalną wadą tego podejścia jest to, że wymaga zróżnicowania wyników w obrębie grupy siostrzanej. Zatem co najmniej u jednej (ale nie u wszystkich) siostry należy zdiagnozować badaną chorobę współistniejącą, co oznacza, że analizą objęte są tylko siostry wykazujące niezgodność. To ograniczenie spowodowało zmniejszenie próby badającej wszystkie wyniki; otyłość (N = 7994 rodziny, N = 17 732 kobiet), depresja (N = 15 232 rodzin, N = 33 709 kobiet), lęk (N = 12 597 rodzin, N = 27 881 kobiet), zaburzenia SSE (N = 5129 rodzin, N = 11 351 kobiet).
Dla każdej konkretnej choroby współistniejącej porównaliśmy wyniki bezwarunkowych modeli regresji logistycznej i siostrzanych modeli FE odpowiednio w próbie Sister i MBR Sister. Podejście FE uwzględnia niezmierzone czynniki wspólne dla rodzeństwa, takie jak geny, które mogą powodować predyspozycje do chorób lub inne czynniki związane ze wspólnym środowiskiem w okresie wychowania, takie jak styl rodzicielstwa oraz podejście do ćwiczeń i diety. Chociaż nie jesteśmy w stanie określić względnego znaczenia każdego z powyższych czynników, metoda pozwala na uzyskanie powiązania po uwzględnieniu czynników wspólnych dla sióstr.
Aby zbadać nasz trzeci cel, w jakim stopniu zmienia się związek między PCOS a wybranymi chorobami współistniejącymi, gdy uwzględni się czynniki wczesnej fazy życia, takie jak masa urodzeniowa, wiek ciążowy i 1-minutowa punktacja w skali Apgar, ograniczyliśmy naszą próbę do pełnych sióstr urodzonych w Szwecji w latach 1973–1973. 1980. Dostępne są informacje na temat ich wybranych cech urodzeniowych (próbka siostrzana MBR).
Analiza wrażliwości
Biorąc pod uwagę niespójność zmiennej wynikowej, a także fakt, że każda kobieta, u której zdiagnozowano PCOS, potrzebuje siostry, istnieje ryzyko, że próba zostanie przesunięta i w ten sposób uzyska wyniki o ograniczonej trafności zewnętrznej w większej próbie reprezentatywnej. Rozwiązujemy ten problem, przedstawiając wyniki modeli oszacowanych na siostrzanej próbie FE, ale bez wspomnianej powyżej FE. Ponadto porównaliśmy te wyniki z odpowiednimi wynikami dla próby bez ograniczeń dotyczących sióstr. Twierdzimy, że zapewnia to dobre przybliżenie stopnia, w jakim próbkę FE rodzeństwa można wykorzystać do zrozumienia powiązań między grupą rodzeństwa o dopasowanych wynikach. Ponadto szacujemy modele losowego przechwytywania na próbie siostrzanej i próbce siostrzanej MBR. Modele przechwytywania losowego są mniej restrykcyjne pod względem badanej próby i możliwości uzyskania estymatorów parametrów dla zmiennych niezależnych, które nie wykazują różnic w obrębie grup rodzeństwa. Wadą jest jednak to, że przydatność metody wymaga braku korelacji między efektami losowymi a zmiennymi niezależnymi. Dlatego skorzystaliśmy z Hausmana (1978). [39] Testowanie specyfikacji w celu wykrycia naruszeń podejścia efektów losowych w założeniach.
Kody diagnostyczne zaburzeń SSE połączono ze względu na ogólnie niską częstość występowania tych schorzeń (odpowiednio 0,64%, 0,40% i 0,64% w całej próbie) i potraktowano je w głównych analizach jako pojedynczą zmienną binarną. Dlatego dla każdego z zaburzeń przeprowadzono odrębną analizę.

„Odkrywca. Entuzjasta muzyki. Fan kawy. Specjalista od sieci. Miłośnik zombie.”
More Stories
Bardziej ekologiczne wybory, bystrzejsze umysły: badania łączą zrównoważony rozwój i zdrowie mózgu
Coraz częstsza liczba chorób przenoszonych przez komary w Europie – jak bardzo martwią się naukowcy? | Transmisja
Badanie asocjacji całego genomu pozwala zidentyfikować genetyczne czynniki ryzyka demencji